Динамическое (спекулятивное) исполнение
Одной из главных особенностей шестого поколения микропроцессоров архитектуры IA32 является динамическое (спекулятивное) исполнение. Под этим термином подразумевается следующая совокупность возможностей:
- Глубокое предсказание ветвлений (с вероятностью >90% можно предсказать 1015 ближайших переходов).
- Анализ потока данных (на 20-30 шагов вперед просмотреть программу и определить зависимость команд по данным или ресурсам).
- Опережающее исполнение команд (МП P6 может выполнять команды в порядке, отличном от их следования в программе).
Внутренняя организация МП P6 соответствует архитектуре RISC, поэтому блок выборки команд, считав поток инструкций IA-32 из L1 кэша инструкций, декодирует их в серию микроопераций. Поток микроопераций попадает в буфер переупорядочивания (пул инструкций). В нем содержатся как не выполненные пока микрооперации, так и уже выполненные, но еще не повлиявшие на состояние процессора. Для декодирования инструкций предназначены три параллельных дешифратора: два для простых и один для сложных инструкций. Каждая инструкция IA-32 декодируется в 1-4 микрооперации. Микрооперации выполняются пятью параллельными исполнительными устройствами: два для целочисленной арифметики, два для вещественной арифметики и блок интерфейса с памятью. Таким образом, возможно выполнение до пяти микроопераций за такт.
Блок исполнительных устройств способен выбирать инструкции из пула в любом порядке. При этом благодаря блоку предсказания ветвлений возможно выполнение инструкций, следующих за условными переходами. Блок резервирования постоянно отслеживает в пуле инструкций те микрооперации, которые готовы к исполнению (исходные данные не зависят от результата других невыполненных инструкций) и направляет их на свободное исполнительное устройство соответствующего типа. Одно из целочисленных исполнительных устройств дополнительно занимается проверкой правильности предсказания переходов. При обнаружении неправильно предсказанного перехода все микрооперации, следующие за переходом, удаляются из пула и производится заполнение конвейера команд инструкциями по новому адресу.
Взаимная зависимость команд от значения регистров архитектуры IA-32 может требовать ожидания освобождения регистров. Для решения этой проблемы предназначены 40 внутренних регистров общего назначения, используемых в реальных вычислениях.
Блок удаления отслеживает результат спекулятивно выполненных микроопераций. Если микрооперация более не зависит от других микроопераций, ее результат переносится на состояние процессора, и она удаляется из буфера переупорядочивания. Блок удаления подтверждает выполнение инструкций (до трех микроопераций за такт) в порядке их следования в программе, принимая во внимание прерывания, исключения, точки останова и промахи предсказания переходов.
Описанная схема отображена на рис. 5.2.
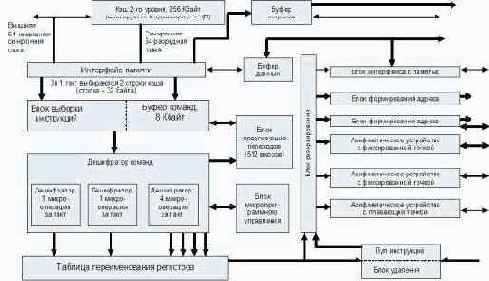
Рис. 5.2. Блок схема микропроцессора Pentium Pro
